



How the Ratings of Chessiverse Bots Work
We try to make the ratings of the Chessiverse bots as accurate as possible, and spend a lot of effort on them. But what actually is an "accurate" rating and how do we set it? Let's take a closer look.
To start things off, it's important to note that the Chessiverse bots will always be a work in progress. We constantly evaluate how they play and do minor tweaks, or major overhauls, as necessary. If you're interested in how they work in more detail, you can read about it in the How Chessiverse Bots Are Created article.
This means that while we aim to have accurate ratings, as time goes by, the ratings might drift, or even jump, and we need to re-calibrate them to make sure the ratings always reflect the expected strength of each bot.
We have done two major calibrations in the past (January 2024 and December 2024), and now it's time for the third one in September 2025.
A rating calibration consists of two main parts.
Establish Relative Ratings
This is the easy part. We play a lot of games between the bots. This establishes their relative strength. For example, if we know that bot A will win 90% of the time against bot B, they should be 400 rating points apart.
The relative rating margin of error can go as low as a couple of rating points.
This means that if you score 50% against Ethan Snide (1057 rating), you should expect to score around 35% against Phil Harmonic (rating 1168). Of course, playing style and openings might have an effect on this (you might perform worse against Phil's opening repertoire), but in general it should hold true.


Scale to a Known Rating System
Now we have relative ratings between the bots. But to be able to relate to these ratings, we want to match them against some external rating as closely as possible.
Basically we want users to be able to know what to expect from a bot, based on their rating.
This is not as easy as it sounds, for many reasons. A rating number might mean different things to different people. When you hear someone say "I'm rated 1500", what do you think that someone is referring to? Is it an established current 1500 rating in classical FIDE tournaments, or is it a four year old peak bullet rating on Chess.com.
Because of this ambiguity, we've experimented with different ways of setting bot ratings. In the past, we've tried several approaches.
Our initial intention was to keep the bot ratings as close to classical FIDE ratings as possible. This turned out to be a bad idea. While most books, and courses, use classical FIDE as reference, it turns out online chess has had a big influence on what players read into a rating. On top of this, players generally don't put as much effort into their games when playing bots.
These two factors made the bots vastly underrated in the eyes of most of our users. Our most common complaint was bots being too hard.
In our previous calibration in December 2024, we decided to change this, and instead we surveyed our users about their external ratings, and then used their performance against the bots as a way of scaling to a known scale. This worked fairly well, but again there is a problem with players generally playing a bit weaker against bots than other humans. But even worse, there's a big difference between users, some use bots as just a training method and test out ideas, and go for crazy sacrifices for the fun of it. While some treat it much more seriously. This becomes a problem when estimating a rating. Two players rated 2000 on Lichess, can have vastly different performances against the bots.
For this third calibration round, which we just finished, we're trying another approach. We introduced four of our bots, across the rating interval, on Lichess and let them get an established rating there. On Lichess they have a mix of games against other Lichess bots and humans, and the rating will be the most up-to-date it can be.
We've used these bots as anchor bots to scale all bots against them. This should give us ratings that are as close as possible to Lichess blitz ratings. Below you'll find the link to Lichess for the bots.



In Summary
- Play a lot of games between the bots to establish their relative rating
- Let a few bots get known Lichess blitz ratings, by letting them actually play on Lichess
- Scale all bots to the known Lichess blitz ratings, attempting to match as close as possible
Why We'll Never Have Perfect Ratings
This all sounds great, but unfortunately there is a problem. A rating system is inherently isolated. It's really only supposed to reflect the relative difference between participants in that particular system. Any mapping or scaling done to mimic a separate system will always be flawed in one way or another.
For example, compare Chess.com and Lichess ratings. The general consensus is that the same player generally has a higher rating on Lichess than Chess.com, with a difference of 200-300 rating points or so. You might be inclined to think that a simple adding of say 250 rating points to a player's Chess.com rating would give a good estimate of their Lichess rating.
And this does hold true for most users, until you get to the extremes. Have a look at IM Eric Rosen's rating, who is active on both platforms. As of the writing of this article his Chess.com blitz rating is 2859, so you would expect his Lichess rating to be well over 3000. But it's actually much lower at 2581. Completely breaking our assumptions.
The reason for this is that the rating distribution is not uniform across all ratings. At lower ratings, Lichess is indeed generally higher. But the higher you get, the more they converge, and at around 2100 rating, Lichess and Chess.com ratings are pretty much the same. While at even higher ratings, the trend reverses, with Chess.com ratings surpassing Lichess instead, as seen in the Eric Rosen example.
Below is a graph with data from chessgoals.com, showing the relationship between Chess.com and Lichess ratings at different ratings. Note how Chess.com starts lower, but ends up higher at the top end.
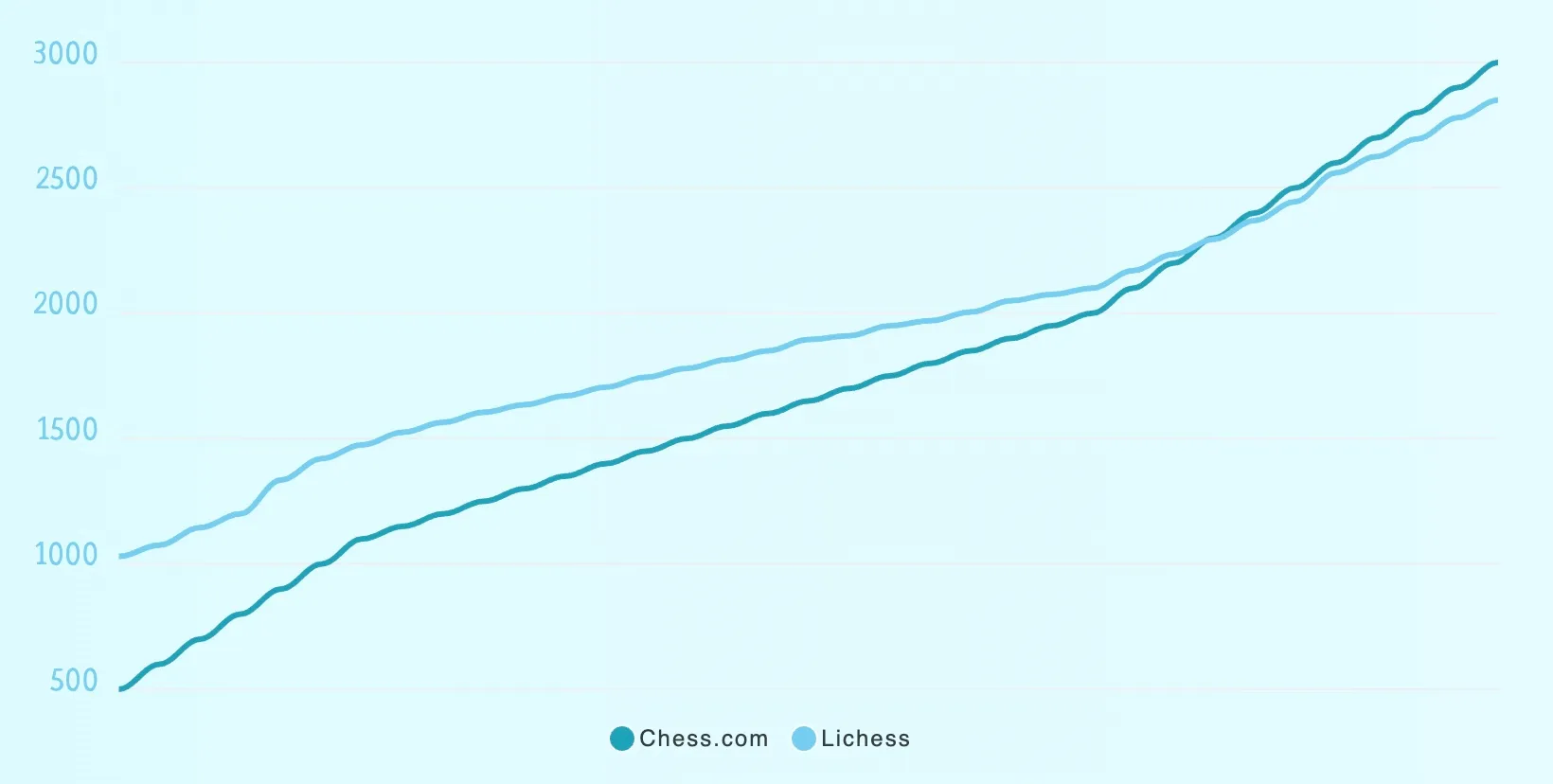
This means that you can't come up with simple formulas to map Chess.com ratings to Lichess ratings. It might work at some rating interval, but will quickly break down at others. With some complex math, you might be able to come up with a mapping function that more accurately maps from one to the other, but as time goes by, this will drift further and further from the truth, and eventually also has to be redone.
This is true for the Chessiverse bot ratings as well. It's very hard to accurately map the ratings to some other system, without some flaws.
However, we still think it's worth giving it a shot. At the very least you will get a ballpark estimate, making it easier to get a rough understanding of the expected strength of each bot. It might not be perfect, but it will be a good indication.
What All This Means for You
This was a long way of saying that as of our last calibration (September 2025), the Chessiverse bot ratings are roughly equivalent to Lichess blitz ratings, and you can look at the Lichess profiles of our four anchor bots to get actual up-to-date ratings.
The ratings are not perfect, and will never be, but they will give you a good indication of what you can expect from each bot.
What's Next
We'll keep improving our bots, and we'll keep doing the calibrations. We think we got it right this time, but only time will tell. We'll monitor how they perform and listen to your feedback.
If you have any questions, feel free to reach out in our Discord, or contact us directly. We're always interested in hearing what you think, in the end we're doing this to make Chessiverse as good as it can be, and our users are the ones who decide if we're succeeding!
Ready to test the ratings yourself? Play chess against computer opponents and see how you compare. You can also check our FAQ for other common questions about Chessiverse.